What are the major differences?
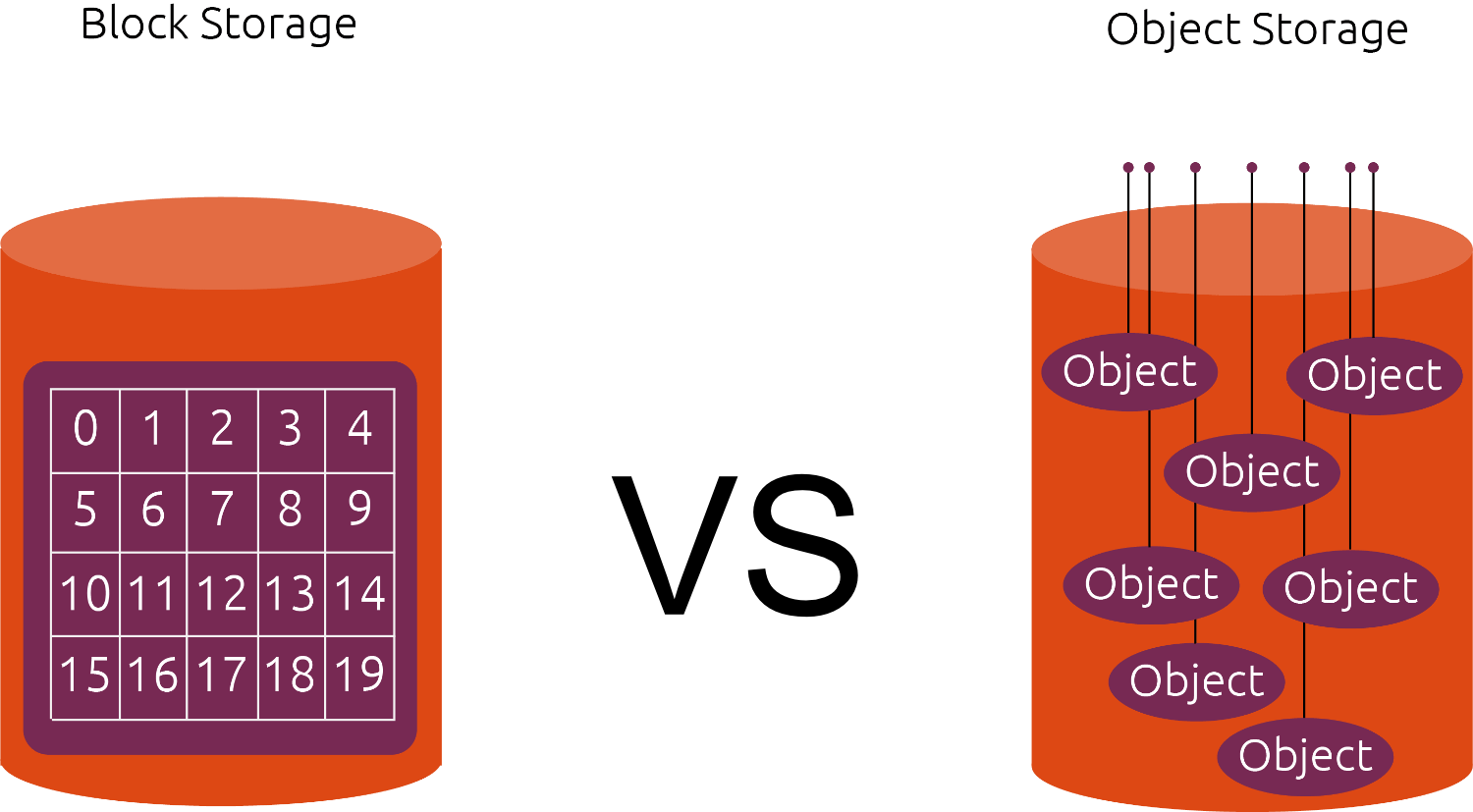
Data Structure:
- S3 Object Storage: S3 is an object storage service, which means it stores data in the form of objects. Each object consists of data, metadata (information about the object), and a unique identifier (the key). Objects are stored in a flat namespace, making it easy to access them using unique keys.
- Block Storage: Block storage, on the other hand, operates at a lower level, storing data in fixed-sized blocks. These blocks can be combined to form a file system or used directly by applications. Block storage does not have built-in metadata; it's mainly concerned with reading and writing blocks of data.
Use Cases:
- S3 Object Storage: S3 is ideal for storing and retrieving large amounts of unstructured data, such as images, videos, backups, log files, and any data that can be represented as objects. It is commonly used for scalable storage and data archiving in cloud environments.
- Block Storage: Block storage is often used for applications that require direct access to low-level storage, such as databases, virtual machines (VMs), and file systems. It's well-suited for scenarios where data needs to be accessed in random or semi-random patterns.
Access Method:
- S3 Object Storage: Accessing data in S3 is through HTTP/HTTPS using the S3 API. It provides a RESTful interface for listing, uploading, and downloading objects, and it's typically accessed over the internet.
- Block Storage: Block storage is accessed at the block level using protocols like iSCSI (Internet Small Computer System Interface) or other proprietary protocols specific to the cloud provider's platform. It is often attached directly to virtual machines or instances.
Data Management:
- S3 Object Storage: S3 offers rich features for data management, including lifecycle policies, versioning, cross-region replication, and access control. It can be used for data backup, data archival, and disaster recovery scenarios.
- Block Storage: Block storage is generally simpler in terms of data management. Snapshots and replication are often provided, but the advanced features of S3 may not be available.
Cost Model:
- S3 Object Storage: S3 typically charges based on the amount of data stored, data transfer, and the number of requests made to the service.
- Block Storage: Block storage is usually priced based on the provisioned storage capacity, with additional costs for data transfer and other features.
In summary, S3 object storage and block storage serve different purposes, and the choice between the two depends on the specific requirements of your applications and data. If you need scalable, cost-effective storage for large volumes of unstructured data, S3 object storage might be the better option. If you require direct access to storage at the block level, and you're dealing with structured data or running applications like databases or VMs, block storage is likely more suitable. In some cases, applications may even use both types of storage in combination to optimize performance and cost.